
How to Collect, Transform, and Ship Logs from AWS S3 to Codegiant Observability Using Vector


It's no longer news that ensuring the reliability and performance of applications is paramount for any organization. Codegiant, as the leading provider of comprehensive DevSecOps solutions, recognizes the importance of empowering teams with robust monitoring tools to achieve these goals. Central to this effort is observability, a concept that goes beyond traditional monitoring by providing deep insights into the inner workings of applications through metrics, traces, and logs. In this blog post, we will discuss observability, focusing specifically on the collection, transformation, and shipping of logs from AWS S3 to Codegiant Observability using Vector.
Codegiant Observability and Vector
Codegiant Observability is a centralized log management solution designed to collect data from any source, live tail logs, and perform real-time analysis. Unlike traditional log management solutions, Codegiant Observability offers a cost-effective and efficient alternative to tools like the Elastic Stack, Datadog and others. With its SQL-compatible structured log management capabilities, teams can easily analyze their logs by writing custom SQL queries, unlocking new insights into their applications' performance and behavior.
Vector is a lightweight and ultra-fast tool for building observability pipelines. As a data pipeline tool, Vector excels at collecting data from various sources, including scraping data or acting as an HTTP server to accumulate ingested data. One of Vector's standout features is its powerful transformation capabilities, which allow users to modify, drop, or aggregate log entries as needed. Built with efficiency in mind, Vector consumes minimal resources while handling substantial amounts of data, making it an ideal choice for organizations looking to streamline their observability workflows. Additionally, Vector's vendor-agnostic nature and compatibility with a wide range of data sources make it a versatile solution for diverse use cases.
Vector's Architecture

At the core of Vector's architecture lies its ability to collect, transform, and forward telemetry data efficiently. Vector operates by collecting data from various sources, and leverages its powerful transformation language, known as the Vector Remap Language (VRL), to manipulate log entries as needed. Following the transformation stage, Vector processes the log messages and forwards them to a designated storage or queue system.
Project Prerequisites
Before diving into the implementation process, let's ensure we have all the necessary prerequisites in place:
Codegiant Account: To use Codegiant Observability, you will need access to a Codegiant account. If you don't have an account already, you can sign up for free on the Codegiant website.
Amazon EKS Cluster: This tutorial assumes you have an Amazon EKS cluster running on AWS.
AWS CLI, kubectl, and Helm: Installation and configuration of the AWS Command Line Interface (CLI), kubectl command-line tool, and Helm package manager are required for interacting with AWS services and managing Kubernetes resources.
S3 Bucket and SQS Queue: You should create a S3 bucket and Amazon SQS queue to store and process log data, respectively.
With these prerequisites in place, we're well-prepared to embark on our journey of setting up the log collection pipeline from AWS S3 to Codegiant Observability.
Project Architecture
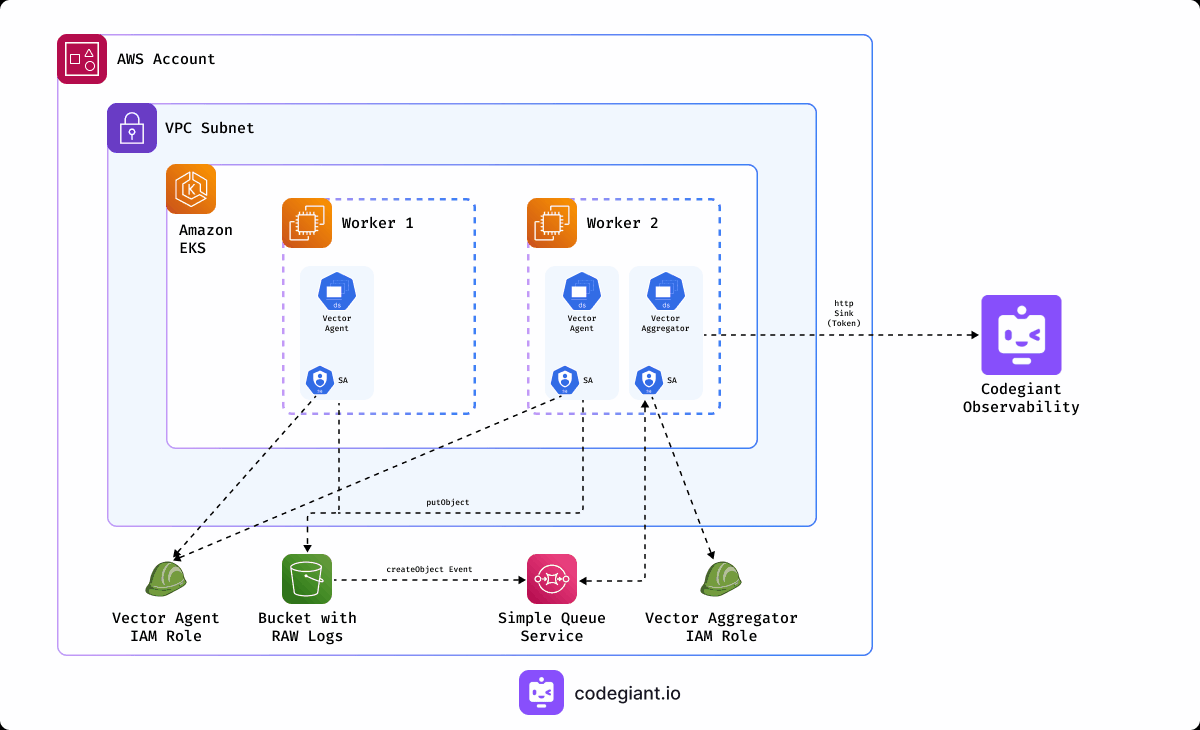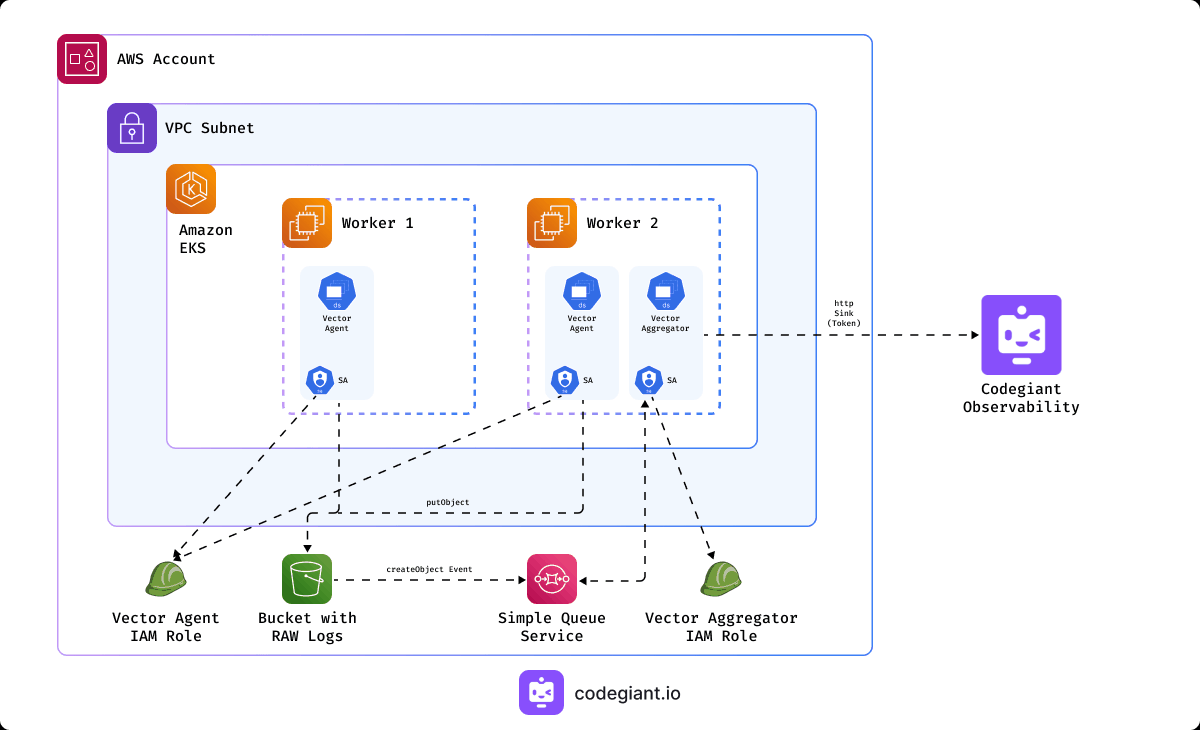
To gain a comprehensive understanding of our project's architecture, let's break down the key components involved:
Vector Agent: Deployed as a DaemonSet, the Vector Agent collects logs from the Kubernetes nodes, including application logs, and sends them to the designated S3 bucket. This process is facilitated by a ServiceAccount and associated IAM Role, ensuring secure access to AWS S3.
Vector Aggregator: Also deployed as a DaemonSet, the Vector Aggregator monitors the SQS queue for incoming log messages, retrieves them from the S3 bucket, trasform, and forwards them to Codegiant Observability.
S3 Bucket: Acts as the storage repository for logs collected from the Kubernetes cluster. It is configured with notifications to trigger events for new log arrivals, which are routed to the SQS queue.
SQS Queue: Serves as the intermediary between the S3 bucket and Vector Aggregator, receiving notifications from the bucket for new log arrivals.
IAM Roles: Two IAM roles, namely VectorAgentRole and VectorAggregatorRole, are created to grant permissions to the AWS resources involved in the log collection and shipping process.
Configuring Kubernetes Environment
Let's use the AWS CLI to update our kubeconfig file to connect to our Amazon EKS cluster. Replace the cluster name and region with your specific details.
$ aws eks update-kubeconfig --region <region> --name <cluster-name>
We should deploy a simple application to the cluster. Create a namespace for the application and deploy an example Nginx app within that namespace to generate logs for demonstration purposes. In my case I used test-ns which you'll see in the vector agent config file later.
$ kubectl create namespace <namespace-name>
$ kubectl create deployment nginx-deployment --image=nginx -n <namespace-name>
You can check to know if the pods are running.
Identity and Access Management Configuration
In order to facilitate secure access to AWS resources from our Kubernetes cluster, we need to configure Identity and Access Management (IAM) roles for service accounts (IRSA). This involves creating IAM roles for Vector Agent and Vector Aggregator, and associating them with their respective Kubernetes service accounts. The IAM roles for service accounts guides will show you how to setup the IRSA. The following is a breakdown of the IAM configurations expected:
VectorAgentPolicy: This policy grants permissions to the Vector Agent pod to list objects in the S3 bucket and put objects (logs) into the bucket. It should be attached to the VectorAgentRole.
VectorAggregatorPolicy: This policy grants permissions to the Vector Aggregator pod to receive and delete messages from the SQS queue, as well as read and write access to the S3 bucket where logs are stored. It should be attached to the VectorAggregatorRole.
Trust Entity for the Roles: This trust policy specifies the conditions under which the Vector Agent or Aggregator pod is allowed to assume its associated IAM role. It ensures that only authenticated requests from the designated service account (agent-vector Or aggregator-vector) within the Kubernetes cluster are accepted.
S3 Bucket Policy: The S3 bucket policy restricts access to the bucket to only the IAM roles associated with the Vector Agent and Vector Aggregator pods.
SQS Access Policy: The SQS policy allows the S3 service to send messages to the SQS queue. This is necessary for the Vector Aggregator pod to receive notifications from S3 when new log files are uploaded.
Once you have configured all IAM permissions, You need to setup a S3 bucket notification for the "ObjectCreated" event, indicating that new objects (log files) have been added to the bucket. These notifications are sent to the SQS queue, where the Vector Aggregator pod can retrieve them and process the corresponding log data.
Creating Soure in Codegiant Observability
In order to add source to our Observability, we need to create an Observability item that centralize log management and analysis. Here are the steps to achieve that:
Create Observability Item: Sign in to your Codegiant account and in the workspace section, Click on the plus icon to create a new item. Select "Observability", and provide a title for your observability item, then click on "Create Observability."

Add Source: Within the newly created observability item, click on "Add Source" to add a new source for log collection. Choose the appropriate platform, in this case, AWS S3, and give it a title.

Retrieve Configuration and Token: Upon adding the source, you'll receive a unique token required for sending data to Codegiant Observability. Additionally, you'll have access to a sample Vector configuration in TOML format, showcasing how to sink data to Codegiant.

Access Configuration (Optional): To access the configuration again after you closed the above modal, go to the settings section and navigate to the added source. Select the source to retrieve the configuration or token. If needed, you can regenerate the token for security purposes.

With Codegiant Observability set up and configured to receive data from AWS S3 via Vector, you're ready to deploy Vector on your Kubernetes cluster and start streaming logs to Codegiant for comprehensive analysis and visualization. Copy the provided Vector configuration and customize it as needed. We will rewrite the configuration in YAML format for the Vector custom config below.
Installing Vector on Kubernetes Cluster
With Codegiant Observability configured to receive data from AWS S3 via Vector, let's proceed to deploy Vector on your Kubernetes cluster.
Prepare Custom Configuration Files: Before deploying Vector, prepare custom configuration files (
agent-config.yamlandaggregator-config.yaml) for the Vector Agent and Vector Aggregator, respectively. These configuration files will specify how Vector collects, transforms, and forwards logs from Kubernetes pods to AWS S3 and then to Codegiant Observability.
# Vector Agent Configuration
# This configuration file defines settings for the Vector Agent,
# responsible for collecting logs from Kubernetes pods and forwarding them to AWS S3.
# Role and Service Account Annotations
role: Agent
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: "arn:aws:iam::ACCOUNT_ID:role/VectorAgentRole"
# Custom Configuration
customConfig:
# Data Directory
data_dir: /vector-data-dir
# API Configuration
api:
enabled: true
address: 127.0.0.1:8686
playground: false
# Sources Configuration
sources:
# Kubernetes Logs Source
kubernetes_logs:
type: "kubernetes_logs"
timezone: "local"
auto_partial_merge: true
extra_namespace_label_selector: "kubernetes.io/metadata.name in (test-ns)"
# Sinks Configuration
sinks:
# AWS S3 Sink
s3:
inputs:
- kubernetes_logs
type: aws_s3
region: "<region>"
bucket: "<bucket-name>"
key_prefix: date=%Y-%m-%d/
encoding:
codec: json
# Avoid Fargate nodes, we can't deploy DaemonSets there and remember to replace the region and bucket name.
Explanation:
Role and Service Account Annotations: Specifies the role and annotations for the Kubernetes service account associated with the Vector Agent. The provided IAM role (VectorAgentRole) ARN grants necessary permissions to interact with AWS services which in this case the S3 bucket.
Custom Configuration:
Data Directory: Defines the directory where Vector will store its data.
API Configuration: Enables the API server and specifies its address. Playground mode is disabled.
Sources Configuration:
Kubernetes Logs Source: Configures Vector to collect logs from Kubernetes pods. It specifies the timezone, enables auto partial merge, and filters logs from the
test-nsnamespace.
Sinks Configuration:
AWS S3 Sink: Configures Vector to forward logs to AWS S3. It specifies the region, bucket name, key prefix with date-based partitioning, and JSON encoding codec for log messages. Logs collected from the Kubernetes logs source are sent to this sink.
# Vector Aggregator Configuration
# This configuration file defines settings for the Vector Aggregator,
# responsible for collecting logs from AWS S3 via SQS and forwarding them to Codegiant Observability.
# Role and Service Account Annotations
role: "Agent"
serviceAccount:
annotations:
"eks.amazonaws.com/role-arn": "arn:aws:iam::ACCOUNT_ID:role/VectorAggregatorRole"
# Custom Configuration
customConfig:
# Data Directory
data_dir: /vector-data-dir
# API Configuration
api:
enabled: true
address: 127.0.0.1:8686
playground: false
# Sources Configuration
sources:
codegiant_mem-s3:
type: aws_s3
compression: gzip
region: "<region>"
strategy: sqs
# SQS Configuration
sqs:
delete_message: true
delete_failed_message: true
poll_secs: 15
queue_url: "https://sqs.us-east-1.amazonaws.com/ACCOUNT_ID/<sqs_name>"
visibility_timeout_secs: 300
# Transforms Configuration
transforms:
initial_transform:
type: remap
inputs:
- codegiant_mem-s3
source: |
.message = encode_base64!(.message)
.message = decode_base64!(.message)
. = parse_json!(.message)
# Sinks Configuration
sinks:
codegiant_http_sink_mem-s3:
type: http
inputs:
- initial_transform
uri: "https://log.codegiant.io"
method: "post"
compression: "none"
auth:
strategy: "bearer"
token: "<TOKEN>"
encoding:
codec: "json"
acknowledgements:
enabled: true
Explanation:
Sources Configuration:
Codegiant Mem-S3 Source: Configures Vector to collect logs from AWS S3 via SQS. It specifies compression, region, and SQS strategy, along with SQS configuration details such as message deletion, polling interval, queue URL, and visibility timeout.
Transforms Configuration:
Initial Transform: Defines a transformation step to decode and parse log messages received from the Codegiant Mem-S3 source. It uses the
remaptransformation type to modify the log message structure. You might wonder why we encode and decode the message, well, that's because S3 adds.gzextension to every log file or simply gzipped it and codegiant compression must be setnone.
Sinks Configuration:
Codegiant HTTP Sink for Mem-S3: Configures Vector to forward transformed logs to Codegiant Observability via HTTP POST requests. It specifies the destination URI, HTTP method, compression, authentication strategy and token, encoding codec, and acknowledgements. The transformed logs from the initial transform step are sent to this sink.
Deploy Vector using Helm: We will utilise Helm to deploy the Vector Agent and Aggregator on your Kubernetes cluster. Use the custom values files created earlier to provide configuration settings for each component. This command will install the Agent and Aggregator as a DaemonSet, and ensuring that it runs on all nodes in the cluster.
$ helm upgrade --install agent vector/vector --namespace vector --create-namespace --values agent-config.yaml
$ helm upgrade --install aggregator vector/vector --namespace vector --create-namespace --values aggregator-config.yaml
After deploying Vector, verify the status of the Vector pods to ensure they are running successfully on your Kubernetes cluster.
$ kubectl get pods -n vector
Additionally, you can inspect the logs of the Vector pods to troubleshoot any issues or errors encountered during deployment.
kubectl logs <pod-name> -n vector
With Vector successfully deployed on your Kubernetes cluster, it will start collecting, transforming, and forwarding logs from Kubernetes pods to AWS S3 and then to Codegiant Observability. You can now monitor and analyze your application logs in real-time using Codegiant's powerful log management and visualization features.
Checking Logs in S3: Confirm that logs are being collected and stored in the designated S3 bucket. You can navigate to the S3 console to view the log files and verify that new logs are being added as expected.

Checking Codegiant Observability: Access your Codegiant account and navigate to your Observability item. You should see incoming log data from the configured AWS S3 source. Verify that logs are being received in real-time and explore the available features for log analysis and visualization.

Conclusion
In conclusion, this blog has provided a comprehensive guide to setting up a robust log collection pipeline from AWS S3 to Codegiant Observability using Vector. We explored the Codegiant Observability, Vector as an efficient data pipeline, steps of configuring IAM roles, setting up AWS S3 buckets and SQS queues for log storage and message queue respectively, deploying Vector components on Kubernetes clusters, and monitoring log flow in Codegiant Observability.
By leveraging the efficiency of Vector and the observability capabilities of Codegiant, teams can gain invaluable insights into their application performance and enhance their DevOps workflows. However, it's worth noting that while this architecture offers flexibility and control, sending data directly to Codegiant with the Vector Agent can provide a more cost-effective solution. It's essential to consider the specific needs of your organization when designing your log management infrastructure. Credit for the initial project architecture goes to opsworks. Please feel free to leave any comments or questions below, and we'll be happy to assist you further.